Diffusion Model (DDPM)
참고 블로그 : 링크
배경지식 : VAE
원본 논문 : 논문
논문의 의의
논문은 매우 복잡하지만 내가 파악한 의의는
기존의 DM에서의 Log-likelihood 형태의 Loss를 MSE 기반의 Loss 형태로 표현해 학습을 쉽게 함!
이다.
Diffusion Model의 기본 구조
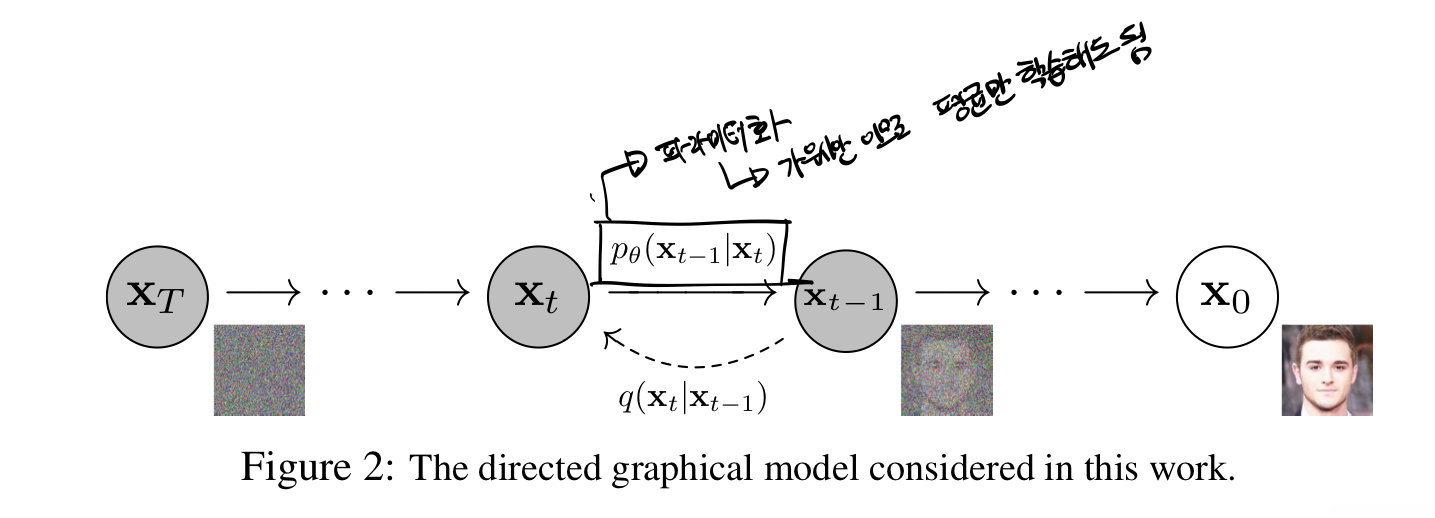
Forward Process
원본 데이터
이 때 각 과정은 Markov Process로 진행되기에, 각 step은 그 이전의 이미지 상태에만 영향을 받고, 노이즈 추가를
Reverse Process
디퓨전 모델은 가우시안 노이즈
이 과정에서 각 step은 파라미터화 되어 있어, 딥러닝 모델을 통해 복원을 수행한다.
이 역시 마르코프 프로세스이다.
각 step을
이 때, denoising 단계는 gaussian이기 때문에 딥러닝 모델은 평균만 학습해도 그만이다.
이 process의 목적은 역시나 기존 이미지와의 Likelihood를 최대화 하는 것이다.
VAE와의 관계?
여기서 순차적으로 노이즈를 추가하고 순차적으로 denoise 하지 않고, 한번에 해버리면 VAE가 된다.
- 원래 input을 어떠한 Gaussian 분포 (latent)로 바꾸는 과정 -> VAE의 인코더 -> Diffusion의 Forward Process
- Gaussian 분포 (latent)에서 다시 원래의 input을 재현하는 과정 -> VAE의 디코더 -> Diffusion의 Reverse Process
그래서 VAE와 Diffusion Model 간의 Loss 등 여러가지는 닮은 점이 많으며, 근본적으로 디퓨젼 모델 역시 Variational Inference를 포함한다고 할 수 있겠다~
Denoising Diffusion Probabilistic Model
이 논문의 목적
이 논문 이전에는 디퓨젼 모델이라는 개념 자체는 제안되었지만, 그 훈련의 과정 및 결과물이 만족스럽지 않았다 (고품질의 이미지를 생성하지 못함)
이 논문에서는 아래와 같은 기여들을 했는데, 도대체 이 기여들이 무엇일까를 알아보는 것이 이번 논문의 도전 되시겠다.
- Diffusion Probabilistic Model과 Denoising score matching간의 novel한 관계가 있다.
- 아래 설명을 보다 보면
과 같은 loss 값이 MSE의 형태를 띄게 된다. 이렇게 단순화된 loss는 사실상 Denoising score matching, 즉 denoise autoencoder에서 노이즈가 얼마나 지워졌는지 단순하게 판단하는 방식과 매우 유사하다는 것이다.
- 아래 설명을 보다 보면
- progressive lossy decompression scheme을 포함한다.
=> "progressive" 각 step 별로 decompression을 하려는 모델이 포함되며, loss도 이 decompression을 잘하기 위하도록 훈련된다. - Diffusion model의 샘플링은 ARM (Auto Regressive Model)의 디코딩과 유사하다.
=> 아무래도 단계별로 분포를 예측하는 것이니깐 유사하다고 볼 수 있다?
(뭔소리야????)
뭔소리인지 모르겠으니 알아보자
Forward Process
여기서
Reverse Process
Forward process에서 가우시안 분포로 noise를 주었는데, 그 역방향 분포도 가우시안 분포라는 것이 이미 증명됨. (받아드리셈 ㅇㅇ)
그래서
여기서
즉 각 step마다 딥러닝 모델을 활용해 어떤 가우시안 distribution으로 denoise를 할지 평균과 분산을 예측하는 것.
Loss Function

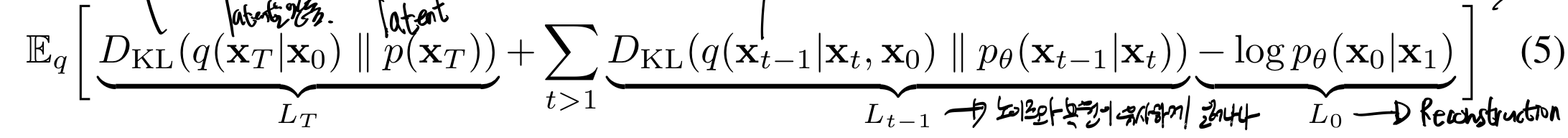
이것을 어떻게 어떻게 전개하면 아래처럼 세 process로 나누어진 loss가 된다.
1. Regularization Error
여기서
그니깐 KL term이 사실상 제로가 된다.
그래서 계산할 필요 없음.
논문에서는 살짝 다르게 설명하는데,
(가우시안 노이즈를 얼마나 줄 것인지 결정하는 파라미터)가 학습이 되지 않는 상수로 진행하기로 했기 때문에, 역시 Regularization Error도 하나의 상수로 결정될 수 있다고 한다. 맞는 소리다. (그리고 역시나 사실상 제로가 되겠지)
2. Denoising Error
여기서
이 정규분포를 알 수 있으니깐,
이러쿵저러쿵.... 증명을 하면 아래와 같이 Denoising Error는 계산 가능하다.
갑자기 결론
그래서 아래처럼 simplified 해서 표현할 수 있다.
그래서 쉽게 학습이 가능하다고 한다 (MSE 같으시잖아 한잔해)
훈련 및 인퍼런스

DDPM Train 과정
- 데이터셋에서 데이터를 샘플링한다.
- 1~
중에 특정 step을 랜덤으로 고른다. (노이즈 스케줄이 정해져있기 때문에 순차적이 아닌 마구잡이로 학습할 수 있다) 를 따르는 노이즈를 샘플링한다. - 이제
을 계산하고 그 그라디언트를 이용해 모델 를 업데이트한다.
DDPM 인퍼런스 과정
- 생성을 시작할 노이즈를
에서 샘플링한다. - 이제
부터 순차적으로 모델 를 이용해서 디노이즈 한다. - 마지막으로 생성 결과
를 리턴한다.
(추가 논의) Diffusion Model은 Image의 Inductive Bias에 어떻게 효율적인가
Latent Diffusion Model (LDM) 논문 중 아래와 같은 내용이 나옴.
Since diffusion models offer excellent inductive biases for spatial data
viT 논문에서 나왔던 image의 inductive bias는 다음과 같다.
- Locality
- translation equivariance
- two-dimensional neighborhood structure
이유
대체로 Denoiser를 CNN 기반으로 사용한다 (e.g. U-Net)
그래서 inductive bias에 fit함
(Latent Diffusion Model (LDM) 마지막 부분 참고하기)
왜 reweighted objective?
마지막 loss를 보면